Chapter 2
ActiveX: A Historical (but Technical) Perspective
- The Application-Centric Environment
- The Road to ActiveX
- ActiveX: Is It Technology or Is It Marketing?
I realize that your temptation to skip a historical perspective chapter in a technical book must be nearly irresistible. But bear with me. In the case of ActiveX, understanding the history can be the most certain road to understanding the technology.
The Application-Centric Environment
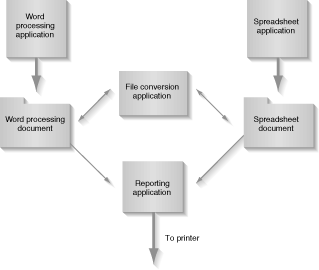
Think back to ancient history, say the mid 1980s. DOS was king, and Windows 1.0 was a slow graphic interface that could actually run on an 8086-based machine from floppy disks. (OK, it didn't run very well, but it did run.) Every task you performed on a PC was application-centric. In other words, each application would work independently, and in most cases would work with its own unique data type. Figure 2.1 illustrates this situation. As long as you were working with the type of data native to the application, everything was fine.
Figure 2.1 : A typical application-centric environment.
{kind=link}
But what if you wanted to convert the data from one program to work with another? In that case, you had to use special conversion programs or depend on the application to have an import or export routine that could handle the desired conversion. If you wanted to create a report that combined two different types of data, you had to use a special report generation program or depend on an application's ability to combine more than one type of data. Sometimes companies came out with application suites that worked together, but in most cases these were just packages of applications that had a better-than-average ability to convert each other's file formats or create reports made up of data from the various applications.
Let's consider a fairly common situation, in which you wished to combine financial data with text in a newsletter or report format. You had a number of possible approaches.
Most high-end word processors contain at least some support for tables. Nowadays that support can be quite extensive and can even include the ability to perform simple calculations across cells, but in the DOS time frame, this capability was still quite primitive. You could create the report using the word processor, create a simple table, and copy the financial information into the table. Of course, any time you changed your spreadsheet, you needed to correct the figures in the text document manually.
Most spreadsheet programs have some capability for adding arbitrary text. In a modern spreadsheet, such as Excel, you can perform a significant amount of text formatting-almost as much as a word processor. But back in the days of Lotus 123, you were limited to adding text to individual cells. If you created your report using a spreadsheet program, the text would look quite plain.
You could export information from the spreadsheet and place it in the word processing document. If you converted the spreadsheet to text, the word processor could probably import the data and display it in a table in the document. Of course you would need to repeat this operation any time the data changed. You could export the data as an image, but this could lead to problems if you tried to scale the image.
You could use a report generation program or desktop publishing application that understood the native data formats involved. This approach sounds perfect, except that most of those programs were limited to a relatively few data formats, were difficult to learn and use, and were limited in scope.
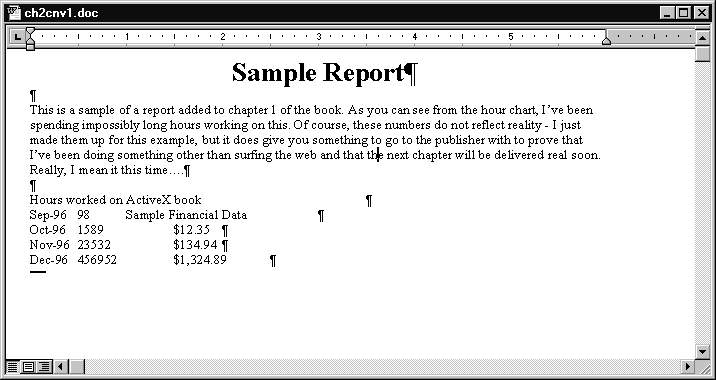
Let's take a closer look at one specific approach: trying to bring the spreadsheet data into the word processing document. Figure 2.2 illustrates converting the spreadsheet data into text and copying it into the document. The result does not look particularly good and does not scale well. You can, of course, proceed to reformat the data using the word processor's capabilities, but this is quite a bit of extra work.
Figure 2.2 : Spreadsheet data imported as unformatted text.
{kind=link}
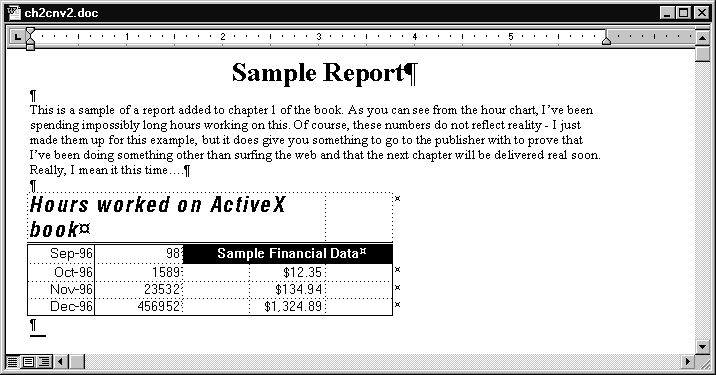
There are a number of common data formats that can be used to transfer formatted text. In this case the word processor is smart enough to recognize this data format and place the imported data into a table format. As you can see in Figure 2.3, the results still leave something to be desired. Scaling the table once again requires manual formatting.
Figure 2.3 : Spreadsheet data imported into a table.
{kind=link}
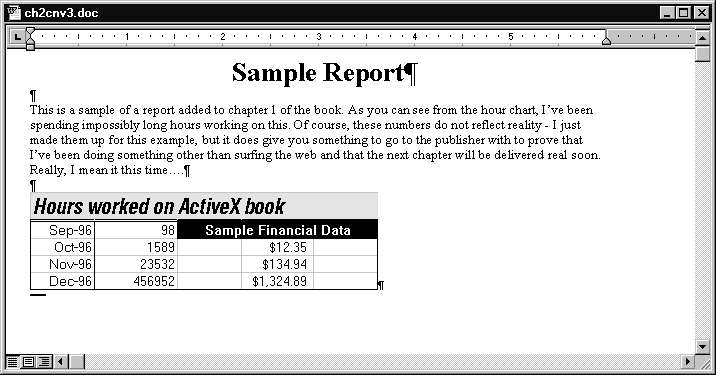
It is possible to obtain a perfect image of the spreadsheet by converting it into a bitmap image, as shown in Figure 2.4. Most word processors are able to handle standard bitmap formats quite well. In this case you are stuck with the image as it exists-you cannot modify the image further without either using a paint program or reconverting the information from the original spreadsheet. Furthermore, bitmap images suffer from severe scaling problems, as shown in Figure 2.5.
Figure 2.4 : Spreadsheet data imported as a bitmap.
{kind=link}
Figure 2.5 : Spreadsheet data imported as a bitmap, then scaled.
{kind=link}
There is one other issue to consider when importing data in the manner shown in the previous four examples: the conversion works only in one direction. In other words, once the spreadsheet data has been converted into a format useable by the word processor, it is extremely difficult to convert the data back to a spreadsheet. In the best case, you could import it back into the spreadsheet but lose most of the formatting information. In the worst case, where the data was transferred as a bitmap, the only possible approach is to manually reenter all of the data.
The Data-centric Environment
One of the key characteristics of an application-centric environment is the conversion process required to move data from one application to another. It might be called conversion, importing, exporting, or cut-and-paste, but the principle is the same in each case. An explicit operation must take place to convert the data between the two data formats, and information is frequently lost in the process.
"Big deal" you may say. "After all, isn't that how most applications work today?"
In many cases you would be right. But we are already beginning to see the results of a fundamental shift in programming. This shift has its roots in a vision that Microsoft began promoting for PCs a decade ago. The idea was that computing should be data-centric instead of application-centric.
What does this mean? It means that instead of users concerning themselves with applications and the files associated with them, a user could be concerned only with the documents they are working with. Documents could contain any type of object, from text to images to sound to types not yet imagined. The users would never have to worry about which type of application they were using. When they opened a document, the operating system would automatically run the code necessary to view or edit the document or any object in the document. The user would never have to worry about the exact representation of the document on disk. The objects for the document might exist on one file or thousands of files and might be present on one disk or distributed throughout a network. If a file was moved, the operating system would keep track of where it was so the document could still find it when necessary.
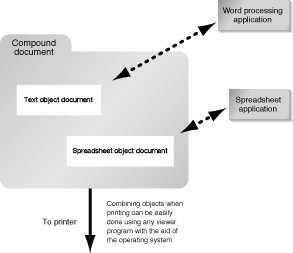
Is this beginning to sound familiar? While most users still think in a somewhat application-centric manner, the transition to data-centric systems is well on its way. One manifestation of this is that users are becoming more and more accustomed to embedding different types of objects inside their word processing or spreadsheet documents. This can be seen in Figure 2.6; the actual Excel spreadsheet object has been embedded into the word processing document. Not only does the image look correct, but it scales very nicely. It does seem somewhat magical that a word processor can understand how to use and display a spreadsheet object in this manner, and-that's the very magic we'll be talking about for the rest of this book. The data-centric approach of embedding a spreadsheet object within a word processing document is shown in Figure 2.7.
Figure 2.6 : An Excel spreadsheet object embedded in a Word document.
{kind=link}
Figure 2.7 : A typical data-centric environment.
{kind=link}
Perhaps the greatest data-centric system in use today is the World Wide Web, where an HTML page can contain images, video, sound, applets and many other types of objects. They can be distributed throughout the world. Yet the user on the system may not even need to worry about launching a browser-they need only ask for a document. The system takes care of launching the browser, and the browser launches any applications needed to use or display the various objects on the page.
Is a data-centric environment actually better for computer users than the familiar application-centric approach? It's a good question, one for which I do not know the answer. In fact, it's probably too soon to answer for sure. Today's implementations of data-centric systems are still not perfect. Lost links on documents when files are moved or servers are down and system configuration problems attest to that fact. But the truth is that as programmers we have little choice in the matter. The transition to a data-centric model of computing is continuing at a rapid pace and will increasingly affect every application you use and write.
Question: What does all this have to do with ActiveX?
Answer: Microsoft is pushing a vision of data-centric computing. ActiveX is Microsoft's implementation of that vision.
The Road to ActiveX
What we call ActiveX today did not appear overnight. Well, the name ActiveX did appear overnight, but the technology did not. It has evolved over the course of years, and knowing about this evolution can both help you understand today's technology and adapt to new technology as it appears.
DDE
The first step on the road to ActiveX was Dynamic Data Exchange (DDE). This capability is still supported by some applications and by Visual Basic, but only for backward compatibility with older applications. Few new applications support DDE to any substantial degree.
DDE was a first step in allowing applications to communicate with each other. This took two forms: data and commands. Applications could send or receive data to and from other applications. Data was identified by the application name and by individual topic and item names within that application. It was also possible to create hot links, so that one application could notify another when information changed.
Applications could also execute commands in another application. For example: if application MyWordProcessor had a macro command called OpenFile implemented via DDE, it would be possible to send an OpenFile execute command through DDE so that the word processor would open a specified file.
DDE was fairly limited, difficult to implement correctly, notoriously slow, and unreliable. It was also a rather application-centric approach to sharing data. It allowed applications to share data but did not allow documents to share data beyond those mechanisms built into the application.
So now that you know a little bit about DDE, feel free to forget most of what you've just read. DDE was a great step, but with one exception it ultimately turned out to be a step in the wrong direction. That exception is its ability to execute commands in other applications, a technology that was the ascendant of today's ActiveX automation.
OLE 1.0
OLE stands for Object Linking and Embedding. OLE 1 was the first step toward implementing one of the most important concepts in data-centric computing: the idea that a document can contain different types of objects. The linking and embedding term suggests the possible locations for objects that are part of a document. They can be embedded within a document, or linked, in which case the document simply contains the name of a file or other reference to the location where the object is stored.
OLE 1 also provided a way for applications to work with these compound documents. Any application could display a document consisting of many different types of objects, and you could double-click on the object in order to edit it using the application associated with the object. Consider the example in Figure 2.7. The document contains a text object and a spreadsheet object. If you opened the document using a word processor, you would see the text and the spreadsheet. The word processor would be able to handle the text directly, but if you wanted to edit the spreadsheet, you would double-click on the spreadsheet object. This would launch the spreadsheet application to edit the object. When you closed the spreadsheet, the object in the document would be updated with any changes you made.
This approach differs in two significant aspects from the application-centric techniques described earlier. First, no conversion takes place. The spreadsheet object remains a spreadsheet, even though it is in some unknown manner being displayed within a word processing application. Because no conversion takes place, no data is lost, and all of the original spreadsheet formatting is preserved. Second, because there is only one spreadsheet object, any changes made to the object from within the word processing application (if such a thing were possible) would affect the actual spreadsheet data. The problem of converting information back from the text document to the spreadsheet does not exist.
OLE 1.0 suffered from one major problem: it was a software technology that was ahead of the available hardware. This was the Windows 2.x and 3.0 era, an age where the 640K base memory limit was still quite real (even 3.0, with its virtual memory, required the lower 640K for many purposes). Attempting to run a large word processing application, such as Microsoft Word, at the same time as a large spreadsheet application, such as Excel, was a slow, frustrating, and often dangerous process. Truly, it was the age of the Unrecoverable Application Error, as compared to the Windows 3.x era, which was the age of the General Protection Fault, as compared to the modern era which is the age of the Exception, or "Your program has performed an illegal operation," which comes in many different flavors.
Despite these limitations, OLE 1.0 was the first real step towards data-centric computing under Windows. And though it did not truly succeed, that's not surprising when you consider for a moment the challenge that implementing a data-centric environment presents.
A data-centric environment requires:
- A way for an application to display objects that it knows nothing about, since a true data-centric application must allow a document to contain any type of object, including those not even imagined when the application was created.
- A way for an application to load and save documents containing objects it knows nothing about.
- A way for an application to provide a visual interface that makes it possible to edit objects it knows nothing about.
And while we're at it, wouldn't it be nice to add:
- A way for an application to execute commands that manipulate objects it knows nothing about.
- A way for an application to support drag-and-drop capability on objects it knows nothing about.
Now, even a beginning programmer knows it's hard enough to work with program data when you know what it is. Manipulating data that your application doesn't even recognize is an intimidating, if not incomprehensible idea. But that's exactly what was needed, and the answer to that challenge was called OLE 2.0
OLE 2.0
In the next few pages, I'm going to attempt a task I suspect is nearly impossible: to provide a clear, understandable explanation of OLE 2.0. I've read quite a few attempts at this, and I must confess I've never been entirely satisfied. I wish I could say I am confident that I can do a better job. All I can say is that I'll do my best. You see, OLE 2.0 is possibly the most complex software technology I've ever seen. I don't think you'll find too many people who understand it completely, and I don't claim to be one of them.
But please don't let me scare you off. And please don't skip this section, going under the assumption that you can understand ActiveX without first understanding OLE 2.0 (the reasons will become obvious by the end of this chapter).
The good news is that you don't need to understand all of OLE 2.0 to use it. This is because much of the complexity is hidden by Visual Basic (and by the Microsoft Foundation Classes, for those of you using Visual C++). In fact, working with ActiveX in Visual Basic is so easy you can create ActiveX components without understanding much of anything. (OK, they may not be particularly good ActiveX components, but you wouldn't be bothering with this book if you didn't know that already.)
I have good reasons for asking you to go through the process of learning OLE 2.0 and ActiveX technology.
- It will help you to understand the language of ActiveX. For example: What is an interface? What is an IDispatch?
- It will help you to not only write good components, but to become a true expert at component development in Visual Basic (and my intent is to help you become nothing less than a guru on the subject).
- It's interesting stuff. After all, aside from being the easiest, most efficient and cost-effective Windows development environment around, VB is widely reputed to also be the most fun.
We'll tackle this technology in two parts. The remainder of this section will focus on the philosophy of OLE 2.0-the ideas on which it is based and the functionality it defines. Information on how it is implemented appears throughout the rest of Part I and is scattered throughout the rest of the book, as well. My hope is that a good understanding of the purpose behind the technology will help you to understand its implementation and its use.
A Technological Stew
The first thing to know about OLE 2.0 is that it is not a single technology. Rather, it is a collection of technologies that have relatively little to do with each other. The most important thing they have in common is they are all based on a standard way of working with objects.
Now, object is one of those words that essentially means whatever you want it to mean. There's object-oriented programming and objects as data structures within a program. But when we talk about objects in the context of OLE 2 or ActiveX, we are referring to a very specific type of object, sometimes called a component object or a window object. These objects follow a standard called component object model (COM). The COM standard defines the following:
- A common way for applications to access and perform operations on objects. This will be the subject of Chapters 3 and 4.
- A mechanism for keeping track of whether an object is in use and deleting it when it is no longer needed.
- A standard error-reporting mechanism and set of error codes and values.
- A mechanism for applications to exchange objects.
- A way to identify objects and to associate objects with applications that understand how those objects are implemented.
Why are these factors important and how do they relate to the idea of data-centric computing? Consider our ongoing example of a document containing text and spreadsheet information in which the document is opened by a word processing application. How can the word processor display a spreadsheet object it knows nothing about?
If the spreadsheet object is a COM object, it's relatively easy. The COM object can support a standard set of functions that tell an object to display itself (COM standard #1). But what does it mean when we say that an object supports a set of functions? The word processor document contains the data for the spreadsheet. (How it keeps the spreadsheet data separate from the text data will be discussed shortly.) The document also contains an object identifier that tells the system the object is a spreadsheet. (Note that it tells the system, not the word processor!) The document does NOT contain the actual functions that draw the object. Those are kept in an application or .DLL that does understand the object, in this case, the spreadsheet application.
Where does the word processing application find the spreadsheet application that contains the drawing functions? It uses the COM mechanism for finding applications that implement objects (COM standard #5). Of course, before displaying the object it may need to launch that application and allow it to access the object's data (COM standard #4). If an error occurs while the spreadsheet object is being displayed by the other application, the word processor will understand the error (COM standard #3). And when both the spreadsheet and the word processor are done with the spreadsheet object, it will be deleted (COM standard #2).
This is a vast simplification of what goes on behind the scenes, but hopefully the point is clear. The common object model makes it possible for applications to manipulate objects they know nothing about. It is the enabling technology for data-centric computing that forms the foundation for everything from future Microsoft operating systems to ActiveX controls to Visual Basic itself.
I called OLE a technological stew. So what other tasty nuggets are contained within this sauce called COM? Here is a brief list of some of the more important features of OLE.
UUID (or GUID or CLSID)
One of the key requirements of OLE is the need to be able to identify objects. When an application works with a document that contains multiple objects, it needs to be able to identify each type of object so the system can correctly identify the application that can manage the object.
To accomplish this, COM assigns every type of object a 16-byte value. This value goes by a number of different names depending on how it is used. UUID stands for Universally Unique Identifier. GUID stands for Globally Unique Identifier. CLSID stands for Class Identifier. IID stands for Interface Identifier.
When you look at a GUID in the system registry, it typically looks
something like this:
| {970EDBA1-111C-11d0-92B0-00AA0036005A} |
Now when Microsoft calls a GUID globally unique, they aren't kidding. Once a GUID is assigned to an object, it is effectively guaranteed to be unique throughout the entire universe, forever. Two factors go into making sure the number is unique. First, part of each GUID is generated based on the network card address in your system (assuming one exists), and every network card built has a unique address thanks to industry standards relating to these cards. Second, a GUID is a very large number, so even if you don't have a network card, a GUID generator program can create a number whose odds of duplicating another are microscopically small.
Visual Basic 5.0 will create GUID numbers for your objects automatically (in fact, you'll have a greater problem cleaning up GUID numbers you don't need than in creating new ones). The important thing to remember is that the objects you create in VB are identified by the GUID-not the object name-so even if you use the same object name as someone else (something you should avoid if possible), your program will still work; it won't confuse the objects.
GUID numbers are also used to identify sets of functions called interfaces, but you'll find out about that later.
Object Presentation
OLE defines standard mechanisms by which objects can be displayed. This means that a container application, such as Microsoft Word, can allocate a space on the screen or on a printed page and allow the object to draw itself into that space. How does this happen? Word knows the GUID of the object and the standard functions the object uses for display (and other purposes). The system can search for the GUID on the registry and find the application or .DLL that contains the actual code for these functions.
But OLE 2.0 goes even farther. It defines a mechanism by which an object's application (server) can take over portions of a document container so you can use all of the tools of that application to edit the object, even though it is still within the same container. This is called in-place editing, and a form of this mechanism is an essential part of what makes ActiveX controls work. Fortunately, Visual Basic automatically handles essentially all of the implementation details of this rather complex technology.
Object Marshaling
OLE defines a mechanism by which objects can be transferred between applications, a process called marshaling. If you are new to 32-bit programming, this may not seem to be a big issue, as it is relatively easy to transfer blocks of memory between processes in 16-bit Windows. However, you will quickly learn that transferring objects between processes is much more difficult under 32-bit Windows. Fortunately, OLE handles most of the work for you. This subject will be covered in much more depth in Chapter 6.
Windows now includes an extended form of COM called Distributed Common Object Model (DCOM). DCOM objects can be marshaled between applications running on different systems on a network.
Compound Documents (OLE Structured Storage)
If a document can contain many types of objects, how can a given container save a document? It would need to understand the file format for each of the objects, an impossible task given that the application may be totally unaware of the nature of the object or how it works. Or would it be?
OLE handles object persistence (loading and saving of objects) in the same way that it handles object display: it is the object's responsibility to know how to load and save itself from a file. Just as OLE defines a set of functions for object display, it also defines a set of functions that can be supported by an object to persist itself.
It might occur to you that this can lead to serious problems. If any one of the objects has a bug in its file I/O code, it could interfere with the portion of the file used by other objects, possibly overwriting and corrupting parts of the file. The problem of storing objects within a file is solved using an OLE technology called OLE Structured Storage. Under OLE Structured Storage, a file is divided into a hierarchy of storages and streams, where a storage corresponds roughly to a directory, and a stream corresponds roughly to a file. In effect, you have an entire file system contained within a single disk file. A container such as Word can create a storage or stream and pass it to the object, telling the object to save itself into the storage or stream. In most cases the container will also save the GUID of the object so when the document is loaded it will be able to determine the type of object that is stored in that particular storage or stream.
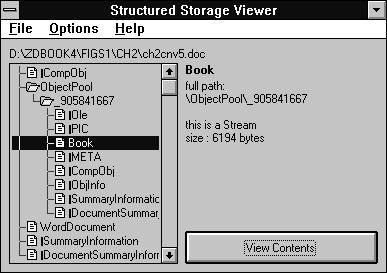
Figure 2.8 shows the contents of an OLE Structured Storage document created by Word for Windows (a .DOC file) containing a spreadsheet document. Storages are indicated by file folders, streams by pages. The text portion of the file is kept in a stream called WordDocument. The spreadsheet object is kept in the ObjectPool storage. The spreadsheet object in turn has as many streams of data as it wishes to use, including, in this case, streams containing summary information about the spreadsheet.
Figure 2.8 : Inside a Microsoft Word .DOC file.
{kind=link}
Drag-and-Drop
Few operations require more cooperation between applications than the ability to drag-and-drop objects from one application to another. Each application must decide what objects the user can select and drag and must provide a reference to that object to the system. It must also decide what types of objects it can accept from other applications and how to handle those objects. OLE 2.0 defines a mechanism for drag-drop operations not only between applications, but between applications and the operating system.
OLE Automation (ActiveX Automation)
This is definitely a case of leaving the best till last. OLE automation is the descendent of DDE's ability to allow one application to execute commands in another application, but it is far more powerful. You see, OLE allows any application to expose any number of objects to the world. OLE automation allows you to execute commands those objects make available or to transfer data to and from those objects.
OLE automation makes it possible for an application to not only call those functions, but to determine at runtime what functions an object has made available and what parameters they require (should the object wish to make that information public).
OLE automation forms the basis for much of the operation of ActiveX components, and it will, in fact, be the focus of the next few chapters. But before we delve further into this subject, there is one more step we need to go through. How do we get from OLE 2.0 to ActiveX? And where do ActiveX controls fit in?
Before we can answer that question, there is one more technology that needs to be discussed. A technology that surprised everyone by its success, and one that has absolutely nothing to do with OLE.
Enter the VBX
In 1991 Visual Basic was released by Microsoft. In this age of Visual Programming, it is sometimes hard to remember that Visual Basic was truly a revolutionary development in Windows programming. Until then, even the simplest Windows application consisted of hundreds of lines of C code. It was common for beginning Windows programmers to take six months of hard study to reach a level of even moderate competence. Overall, Windows programming was a complex and rather unpleasant experience.
Visual Basic changed all that. You could write a simple Windows application in minutes. For the first time it was possible to write trivial throwaway Windows applications for simple tasks. Windows programming was even fun.
Visual Basic did this by encapsulating much of the complexity of Windows into the Basic language. The forms layout package made creating a user interface easy. (Note that I did not say it made making a good user interface easy. VB makes it as easy to create a bad user interface as a good one-maybe easier.) You simply dropped controls onto forms. These controls had properties you could set from your application. The values of these properties could be set at design time and stored in the application. Most controls had their own user interface as well-they were displayed on the form and could be clicked or otherwise manipulated at runtime.
If this was all Visual Basic did, it would be a remarkable product. But Visual Basic's developers took things one critical step further. They made the language extensible. First, they made it possible for Visual Basic to directly access functions in dynamic link libraries, especially those in the Windows API. (My first book, the Visual Basic Programmer's Guide to the Win32 API, and its successor, Dan Appleman's Visual Basic 5.0 Programmer's Guide to the Win32 API, both from ZD Press, discuss this subject at length.) Next, they made it possible to add custom controls (VBX) to Visual Basic in such a way that they appear to the programmer as if they were built into the environment itself. They appear in the toolbox and behave exactly like those controls that are built into the language.
All of a sudden an entire industry sprang up to create and market a wide variety of custom controls for almost any imaginable application. (I founded a company myself, Desaware, for the sole purpose of developing Visual Basic custom controls.) An amazing synergy then took place. The availability of a wide variety of custom controls made Visual Basic more powerful and more popular. The presence of a large Visual Basic market allowed VBX developers to amortize their costs across a large customer base, allowing them to sell their controls at prices far below what it would cost a programmer to develop the same functionality on their own. This was essential because VBXs, being written in C or C++, were notoriously difficult to write-far more difficult than programming in Visual Basic. Meanwhile, Microsoft consciously supported the custom control market by encouraging and promoting these third-party vendors.
You see, Visual Basic not only realized the dream of easy Windows programming. It realized the dream of component-based programming. It made it possible to develop complex applications that are built up from low-cost reusable software components. The combination served to make Visual Basic the enormous success that it has become, selling far more copies than languages such as C or C++.
Now let's back up for a moment and reconsider the characteristics of a custom control. It is an object of a sort. It contains data. The part of the data that is set at design time can be saved in a project file, and each custom control knows how to save its own data. Visual Basic can support any type of VBX, because each VBX contains a standard set of functions that Visual Basic can manipulate. A custom control can have a visual appearance, and each VBX is responsible for drawing itself when instructed to do so by the Visual Basic environment. An executable contains the persisted data for a custom control, but the implementation of the control-the functions that make it work-is kept in a separate dynamic link library with the extension .VBX. Visual Basic stores with the executable, on a form, not only the data for each instance of the control (each control object), but also information identifying the control so it can load the correct VBX for each object.
Does any of this sound familiar? It should. Those are the same characteristics we described earlier for an OLE 2.0 object. Now, let me stress: A VBX is not a COM object. It is based on its own VB-specific technology that is implemented only in 16-bit Windows for VB3, 16-bit VB4, and environments that have tried to be more or less compatible with the VBX standard.
Enter Visual Basic 4.0
Visual Basic 1.0, as revolutionary as it was, was grafted from a number of existing technologies. It used a Basic language engine that was written in 16-bit assembly language. This language engine was grafted onto a forms package architecture called Ruby, which was originally developed by Alan Cooper, the father of Visual Basic. Clearly, Visual Basic as it was implemented in version 1.0 through 3.0 was not a sound foundation for the long term, especially with regard to the new 32-bit operating systems then under development. Microsoft therefore began work on a language engine called Object Basic, which is now known as VBA, or Visual Basic for Applications. This would become the underlying programming language not only for Visual Basic 4.0 and its successors, but for all of the Microsoft applications, or at least the programmable ones. In fact, Microsoft is now licensing VBA for use in non-Microsoft applications as well.
VBA was a complete redesign and rewrite of the language engine. Most of the details of what has changed are mysteries known only to Microsoft developers, but the most important one is clear. VBA is based on COM.
What does this mean? It means that VBA is built up of objects that are true OLE objects. Not only does VBA use OLE automation to program other objects and applications, it uses OLE internally to execute commands on its own objects. It also uses OLE when you create your own objects that can then be used either from within VBA or made public and used from other applications.
When Microsoft developers rebuilt Visual Basic 4.0 on COM technology, they knew they still needed to support custom controls. But they also knew that VBX technology was obsolete. What they needed was an OLE equivalent. Fortunately, they almost had one already. You see, OLE already provided the ability for objects to be placed in containers. Those objects could already be programmed using OLE automation. They already had the ability to save themselves into files. The only thing those objects could not do was raise events.
The answer was simple. Extend OLE. A new type of object was defined called an OLE control (OCX), which defined a way for controls to raise events in the container application. It also defined some new functions to improve performance and add some additional capabilities. Not only were OLE controls compatible with Visual Basic 4.0, but they could be used with minor modifications by virtually any OLE container.
To say that the answer was simple is perhaps misleading. The implementation of this technology is complex and took quite a while to develop. And it is still evolving. But OLE is by its very nature extendible. You'll find out how and why this is so as you read on, because you'll be using the same techniques to extend your own objects.
ActiveX: Is It Technology or Is It Marketing?
Let's review for a moment.
We started out by looking at the problems related to building complex documents in an application-centric environment.
We then took a look at what a docu-centric environment would be like, and what it would require.
We then saw how COM made it possible to implement many of the technologies that a docu-centric environment would require.
We saw that OLE was not one technology, but a whole set of technologies that are seemingly unrelated except for the fact that they are based on COM and relate to docu-centric environments.
We saw that Visual Basic combined with VBX custom control technology, became an extremely successful platform for component-based software development, but that it was not viable in the long term.
Finally, we saw how Visual Basic 4.0 was built on VBA, a COM-based language engine, and how OLE was extended to include OLE controls, a COM-based custom control technology.
As you can see, the technology has been evolving towards a more docu-centric approach for years. Yet the process is still very much in its early stages.
So far we've been talking about OLE 2.0. You may be wondering where ActiveX comes in. The answer may surprise you. But before proceeding, I want to clarify one thing. I am not an employee of Microsoft, and aside from a brief contract job several years ago, have never worked for them. Much of what I know about Microsoft and how it works is based on informal discussions with Microsoft employees, information they make public, reports in the media, an understanding of the technology, and, sometimes, sheer speculation. So, while I have little, if any, inside information that a Microsoft employee might have, I do have a correspondingly greater freedom to share my opinions. I don't have to adhere to the "party line."
That said, here is the truth about ActiveX as I know it.
Think of the world as it existed in late 1995 and early 1996. Visual Basic 4.0 was shipping, and OLE was well on its way to establishing a dominant standard for object embedding and programming. It was driving Microsoft's vision for docu-centric computing.
Then, as if from nowhere, the Internet frenzy, specifically the World Wide Web, went into a growth curve of hyperbolic proportions. Now, I truly believe that much of what you read about the Internet is overblown media hype. Much of the investment in Internet-related products and companies is going to prove to be a waste of money. It is still way too early to forecast what will happen with the Internet, what kinds of markets will develop, and what its impact on society will be in the long run.
I do know enough about Microsoft to know that, as chaotic as it may be sometimes as an organization, it is an organization that includes a large number of extremely bright people. Yet, on the surface, it looks as if their collective reaction to the Internet was nothing short of panic. All of a sudden, Microsoft had a strategy that seemed to be: "Whatever we do must have an Internet component." Surely Microsoft was not actually afraid of Netscape? Could the Internet really challenge Microsoft's vision of a computer on every desktop running Microsoft software on Microsoft operating systems? (By the way, when I describe this as their vision, I'm not being critical. This is, as near as I can tell, their actual corporate vision. If you don't like the idea, that's your judgment call.)
It was only when I began outlining this book that it became clear to me. I don't think Microsoft was afraid of Netscape as a company. I think they were suddenly tremendously afraid of the World Wide Web as a vision. You see, the trend towards a Windows-based docu-centric programming scheme was well under way when, all of a sudden, here came the World Wide Web, an environment clearly docu-centric by nature. Why, HTML pages routinely contain all sorts of objects from formatted text, to picture, to sound, to video. With Java, Web pages can include code-based objects. HTML is easily extendible to include other types of objects as well. HTML documents are easy to create, and becoming easier as advanced tools become available.
In a way, the Web presents a conceptual leap over Microsoft's approach. Application programmers are only now getting used to the idea of embedding different types of objects in word processing documents or spreadsheets, where these objects are typically located on the same system or maybe a local network. Web programmers start with the fundamental understanding that documents can and should be built up of pages of different types, where each page may exist anywhere in the entire world. HTML is limited when compared to OLE technology, but it promotes a way of thinking that could jeopardize Microsoft's approach towards docu-centric computing.
I believe this is why Microsoft panicked. They weren't afraid of Netscape. They were afraid that the World Wide Web (including HTML, Java, and a non-COM-based object standard) would become the dominant implementation of a docu-centric programming environment.
So Microsoft changed its approach. They adopted the Internet. This was easier than it might seem. OLE was, by its very nature, extendible. It wouldn't take much effort to add a few Internet extensions and make OLE a strongly competitive mechanism for implementing compound documents on the Internet in a way that was fully compatible with HTML.
But technology isn't everything. Perceptions count as well. Microsoft needed an Internet message. They needed to show the world they were serious about the Internet. They didn't really have an Internet-specific technology yet, but they needed a dramatic way to show they would have one soon and a sound technological foundation that would clearly become viable on the Internet.
Here's what they did: They renamed OLE and called it ActiveX.
OLE is ActiveX. It's that simple. ActiveX automation is OLE automation. All OLE controls instantly became ActiveX controls. They were not all Internet-enabled ActiveX controls (some very useful controls have nothing to do with the Internet), but they were all, by definition, ActiveX controls. ActiveX code components are OLE servers. The name has changed, but the technology is the same. ActiveX documents are Doc Objects.
I can't stress this enough. Microsoft's marketing team has gone to great lengths to promote ActiveX as an Internet technology. This is essential from their point of view because Microsoft desperately wants it to be the dominant object technology on the Internet and on corporate intranets. But as a Visual Basic programmer, you may find that the Internet is the least important aspect of ActiveX in your own efforts. Visual Basic 5.0's ability to create ActiveX controls may prove a good way to create flashy Web pages. It will become the most powerful tool for component-based application development yet created. Of that I am certain.
Rest assured, this book will discuss how to deploy ActiveX controls and ActiveX documents (previously called doc objects) on the Internet. But the emphasis will be on the technology in general and on the ways you can use this technology to craft great applications that may or may not be Internet based.
This concludes our historical perspective. From now on, I'll usually refer to the technology as ActiveX, but you'll know that it and OLE are one and the same. Now it's time to take a look at how this is implemented, at least at the Visual Basic level.



